A research on different algorithm perform on sentiment analysis with different size dataset
RESULTs
Logistic Regression
In the Logistic Regression, we first randomly chose 500 positive samples and 500 negative samples as testing set.
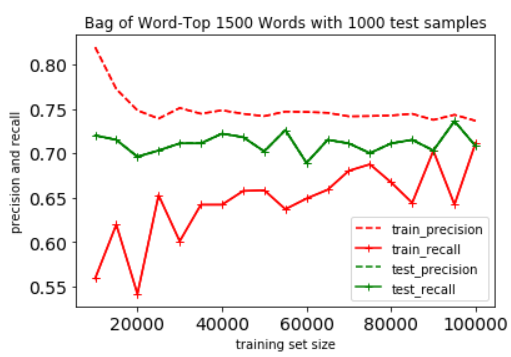


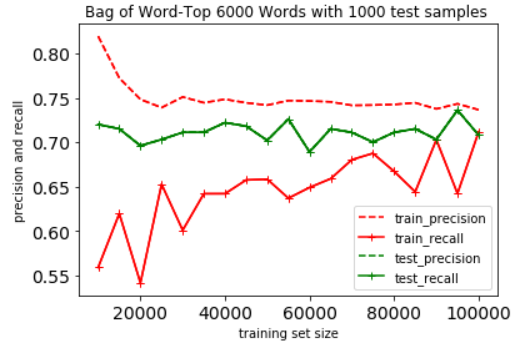

Decision Tree
Because we didn't use pruning strategy to this, there is a apparent overfittig in trainnign model


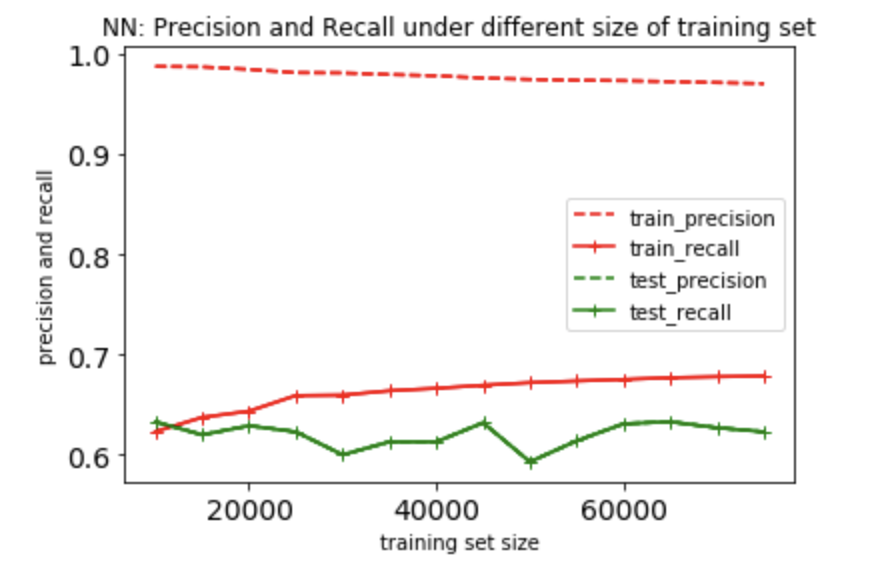
Nearest Neighbor
A probable reason for this performance is that in 1-NN, each training data sample is the nearest neighbor for itself, but when K is greater than 1, each training data sample should consider others.

LSTM
Precision and Recall not good as we want but test accuracy is acceptable. With larger dataset input result should be better


Naive Bayes
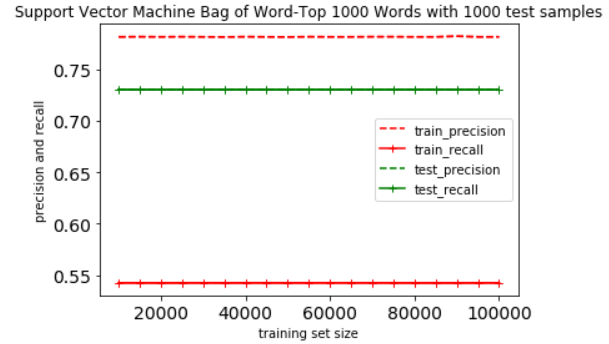
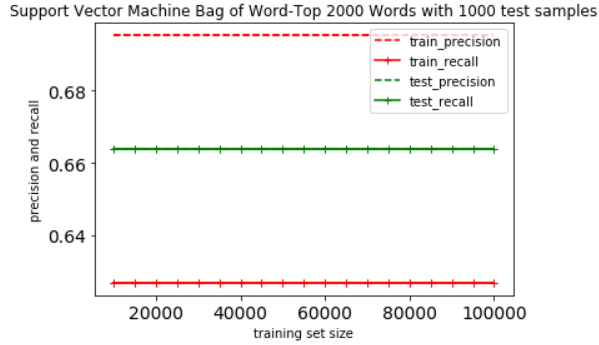
Their performance is irrelevant to the size of training set. Their precision and recall value stay at a constant value for whatever size of the training set.


Support Vector Machine
This shown Support Vector Machine classifier is not very effective when handling a very sparse vector